
Baskin Engineering postdoctoral scholar Oskar Elek and graduate student Henry Zhou are exploring the complex and not fully understood abstract spaces where machines process human language. They hope to find new ways to improve machine language processing, which in turn will advance artificial intelligence (AI) technology.
A critical point of inspiration for Elek and Zhou’s research was 20th century French philosopher Gilles Deleuze’s belief that thought and knowledge are not hierarchical but are instead network-like structures. Deleuze often referred to a rhizome, a continuously growing horizontal underground stem which branches out at different points, to visualize the concept that thoughts and ideas are interconnected structures and follow a non-hierarchical form.
If thought and ideas do not follow a hierarchy, then what about language?

Elek and Zhou assert that language is displayed as a network of interconnected structures, resulting in no real predetermined organization.
“In language, these structures can be seen as a kind of abstract ‘scaffolding,’ connecting words within and across different semantic contexts,” said Elek.
Understanding this geometric, abstract structure of language was a driving force for Elek and Zhou to further explore the intricacies of human language so we can improve how AI machines process human language, a necessary function for a machine to perform humanistic tasks correctly.
A new approach to understanding how language is processed in AI algorithms
The research project, which originated in Associate Professor of Computational Media Angus Forbes’ Creative Coding Lab, uses a new methodology to explore word embeddings—a form of data in natural language processing (NLP) that allows machines to process written text in a high-dimensional, very abstract space. Tokens—which is a technical way of describing elements of language (words) for this research project—are given numerical values, mapped into that abstract space, and then grouped accordingly by spatial proximity.
“Traditional machine learning language modeling determines similarity of words based on spatial proximity in that high-dimensional space, which can lead to grouping words together that have completely different contexts and meanings,” Zhou said. This grouping of words that have different meanings and are not similar could lead to decreased performance of tasks by the machine.
Zhou and Elek’s research aims to counteract this deficit in standard machine learning language processing by accounting for the semantics of words in word embeddings and measuring the similarity between two words, beyond their proximity in space.

The paper: Bio-inspired Structure Identification in Language Embeddings
Lead authors Zhou and Elek, with contributions from Computational Media Associate Professor Angus Forbes and Linguistics Professor Pranav Anand, published their research in fall 2020.
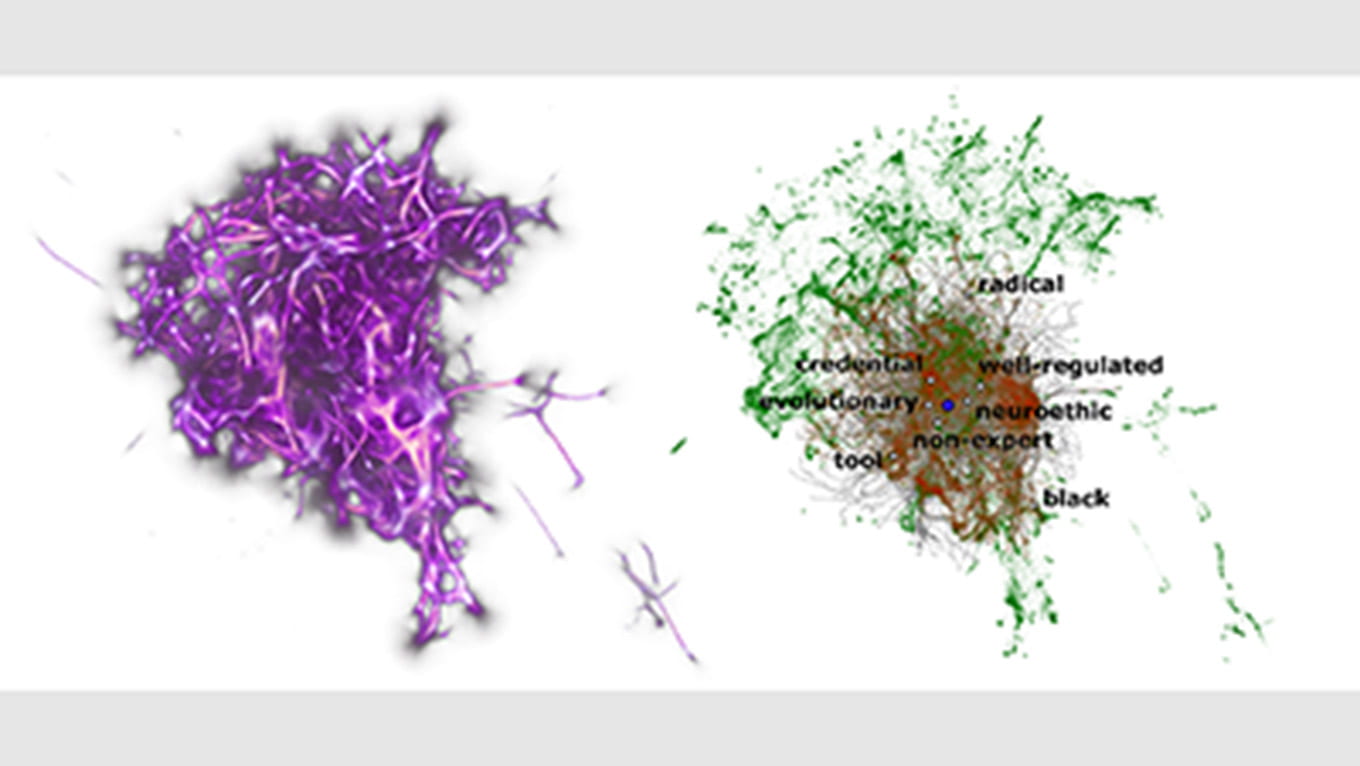
In their paper, “Bio-inspired Structure Identification in Language Embeddings,” they outline their research method of applying the Monte Carlo Physarum Machine (MCPM) algorithm to word embeddings in NLP by measuring the similarities of words beyond their numerical point in space to better understand the word embedding space.
“MCPM is an algorithm that finds hidden structure in data, inspired by the biological phenomenon of a slime mold’s growth and foraging behavior, which moves in ways that exerts least effort,” described Elek, signifying the “bio” reference in their paper’s title.
The research brings forth terminology that allows us to better describe the ways words can be connected in a machine’s word-embedding space used to process human language.
An island acts as a way to visualize multiple “knots” together, which are clusters of words, and a filament is a word that connects to islands. This entanglement of words reveals how complex and interconnected the structure of human language is and proves the importance of how interpreting language in a machine goes behind just grouping words together by proximity.
“Machine learning methods have become ubiquitous, especially in processing images and natural language. Yet machine learning is notorious for creating human-unreadable data and learning in a black-box manner,” said Zhou.
“We believe that our method provides a new way to interpret and extract salient information from this difficult form of machine learning data. It is also a visually intriguing way to explore seemingly impenetrable data.”
In addition to applying the algorithm to extract hidden data of language structures in NLP, both researchers were interested in creating 2-D and 3-D visual representations of their data.
By crafting a visual representation of their findings, both researchers are able to display information taken from the hundreds of dimensions that AI machines work out of into a lower dimensional space. This 2- or 3-D space allows for better comprehension of how machines group together individual tokens to process human language. Creating visual representations of data is a key highlight of the work being done in the Creative Coding Lab.
“We have managed to not only visualize these implicit network structures in language but also use the MCMP algorithm to accomplish basic language processing tasks, such as finding words that are semantically related to a given query word,” said Elek.
On-going research goals
Zhou and Elek say that this is a new approach to understanding and interpreting language in machine learning, and their short term goal is to use Monte Carlo Physarum Machine (MCPM) as a method to reveal more about word embeddings and discover patterns in natural language processing.
In the long term, both researchers hope to develop new tools that allow for more efficient and objective processing of human language in AI machines, including creating automizations for processing large amounts of text.
“We would like to understand the nature of structures that have evolved in language and use that to gain insight into modern machine learning methods,” said Elek. “This is just the beginning of our findings, and we’re looking forward to continuing our research in this important field.”
__
Lead authors Zhou and Elek presented their research findings at the Visualization for Digital Humanities Conference in fall 2020.
To learn more about the various research projects completed in the Creative Coding Lab, please visit the Lab’s webpage.


